DIADEM: DIAgnosis of DEtection Models¶
Training and Analysing a Detection Model before Deployment.
DIADEM trains and evaluates detection models (supervised, semi-supervised and unsupervised). It hides some of the machine learning machinery (feature standardization, setting of the hyperparameters) to let security experts focus mainly on detection. Besides, it comes with a graphical user interface to evaluate and diagnose detection models.
References
Beaugnon, Anaël, and Pierre Chifflier. “Machine Learning for Computer Security Detection Systems: Practical Feedback and Solutions”, C&ESAR 2018.
Beaugnon, Anaël. “Expert-in-the-Loop Supervised Learning for Computer Security Detection Systems.”, Ph.D. thesis, École Normale Superieure (2018).
[FRENCH] Bonneton, Anaël, and Antoine Husson, “Le Machine Learning confronté aux contraintes opérationnelles des systèmes de détection”, SSTIC 2017.
Usage¶
SecuML_DIADEM <project> <dataset> <model_class> -a <annotations_file>.SecuML_DIADEM <project> <dataset> <model_class>.Semi-supervised and supervised model classes require annotated data.
DIADEM can be launched with the ground truth annotations
with -a GROUND_TRUTH or with a partial annotation file
with -a <filename>.
See Data for more information about ground truth and partial
annotations.
Note
These arguments are enough to launch DIADEM on a given dataset. The parameters presented below are completely optional.
The following sections present the model classes available, and some optional parameters for setting the hyperparameters and selecting a specific validation mode. If these parameters are not provided, DIADEM uses default values for the hyperparameters, and splits the input dataset into a training (90%) and a validation dataset (10%).
Model Classes¶
Supervised Model Classes¶
LogisticRegression (scikit-learn documentation)
GaussianNaiveBayes (scikit-learn documentation)
DecisionTree (scikit-learn documentation)
RandomForest (scikit-learn documentation)
GradientBoosting (scikit-learn documentation)
Unsupervised Model Classes¶
IsolationForest (scikit-learn documentation)
OneClassSvm (scikit-learn documentation)
EllipticEnvelope (scikit-learn documentation)
Semi-supervised Model Classes¶
LabelPropagation (scikit-learn documentation)
WeighedIsolationForest (new implementation 1)
Sssvdd (new implementation)
SecuML_DIADEM <project> <dataset> <model_class> -h.References
- 1
Siddiqui et al., “Feedback-Guided Anomaly Discovery via Online Optimization”, KDD 2018.
Applying a Previously Trained Detection Model¶
DIADEM can apply a previously trained detection model with the following command line:
SecuML_DIADEM <project> <dataset> AlreadyTrained --model-exp-id <exp_id> \
--validation-mode ValidationDatasets --validation-datasets <validation_datasets>
In this case, there are two restrictions:
--model-exp-idmust correspond to a DIADEM or an ILAB experiment ;ValidationDatasetsis the only validation mode available.
Hyperparameters¶
Some model classes have hyperparameters, i.e. parameters that must be set before the training phase. These parameters are not fit automatically by the training algorithm.
For example, logistic regression has two hyperparameters: the regularization
strength, --regularization, and the penalty norm, --penalty.
The number of trees, --n-estimators, is one hyperparameter of random
forests among many others.
Hyperparameters Values¶
To list the hyperparameters of a given detection model see the
Hyperparameters group of the help message displayed by
SecuML_DIADEM <project> <dataset> <model_class> -h.
For each hyperparameter, the help message displays its name and its default
value.
Semi-supervised and unsupervised model classes accept only a single value for each hyperparameter. On the contrary, supervised model classes accept a list of values for each hyperparameter, and the best combination of hyperparameters is selected automatically with a cross-validation grid-search.
Automatic Selection¶
In the case of supervised model classes, DIADEM selects the best combination of hyperparameters automatically. It considers all the combinations of hyperparameters values in a grid search to find the best one. First, DIADEM evaluates the performance (through cross-validation) of the detection model trained with each combination, then it selects the one that results in the best-performing detection model.
DIADEM allows to parametrize the grid search:
[optional]
--num-folds: number of folds built in the cross-validation (default: 4);[optional]
--n-jobs: number of CPU cores used when parallelizing the cross-validation, -1 means using all cores (default: -1);[optional]
--objective-func: the performance indicator (Ndcg,RocAuc,Accuracy, orDrAtFdr) to optimize during the grid-search (default:RocAuc). ;[optional]
--far: the false alarm rate (far) to consider if--objective-funcis set toDrAtFdr.
These options are listed in the Hyperparameters Optimization group of the help
message displayed by
SecuML_DIADEM <project> <dataset> <supervised_model_class> -h.
Validation Modes¶
DIADEM offers several validation modes, i.e. ways to build the training and the validation datasets. Temporal validation modes (Temporal Split, Cutoff Time, Temporal Cross Validation, and Sliding Window) should be preferred when the instances are timestamped since they better reflect real-world conditions. These validation modes ensure that no instance from the future is used when the detection model is trained: the training instances predate the validation instances.
Random Split¶
--validation-mode RandomSplit --test-size <prop>
<prop> instances of <dataset> are selected uniformly for the validation
dataset. The remaining instances constitute the training dataset.
Temporal Split¶
--validation-mode TemporalSplit --test-size <prop>
The <prop> most recent instances of <dataset> are selected for the
validation dataset. The remaining instances constitute the training dataset.
Cutoff Time¶
--validation-mode CutoffTime --cutoff-time <cutoff_time>
The instances of <dataset> with a timestamp before <cutoff_time>
constitutes the training dataset, and the instances after constitute the
validation dataset.
<cutoff_time> must be formatted as follows:
YYYY-MM-DD HH:MM:SS.
Cross Validation¶
--validation-mode Cv --validation-folds <num_folds>
The dataset <dataset> is divided uniformly into <num_folds> buckets.
Each bucket has approximately the same number
of instances and the same proportion of benign/malicious instances as the whole
dataset.
The detection model is trained <num_folds> times: each time, one bucket is
the validation dataset and the other buckets form the training dataset.
Example with \(\text{num_folds} = 4\):

Temporal Cross Validation¶
--validation-mode TemporalCv --validation-folds <num_folds>
The dataset <dataset> is divided into <num_folds> + 1 buckets.
Each bucket \(b_{i \in [0,~\text{num_folds}]}\) contains instances
occurring between \(t_i^{max} = T^{min} + i \cdot \Delta\)
and \(t_i^{max} = T^{min} + (i+1) \cdot \Delta\)
where
\(T^{min}\) and \(T^{max}\) correspond to the timestamps of the oldest and latest instances ;
\(\Delta = \frac{T^{max} - T^{min}}{\text{num_folds} + 1}\).
For each fold \(f\in[0,\text{num_folds}-1]\), the buckets from \(b_0\) to \(b_f\) constitute the training dataset, and the remaining buckets form the validation dataset.
Example with \(\text{num_folds} = 4\):

Sliding Window¶
--validation-mode SlidingWindow --buckets <n> --train-buckets <n_train> --test-buckets <n_test>
The dataset <dataset> is divided into <n> buckets
just as in the case of Temporal Cross Validation.
Each bucket \(b_{i \in [0,~n-1]}\) contains instances
occurring between \(t_i^{max} = T^{min} + i \cdot \Delta\)
and \(t_i^{max} = T^{min} + (i+1) \cdot \Delta\)
where
\(T^{min}\) and \(T^{max}\) correspond to the timestamps of the oldest and latest instances ;
\(\Delta = \frac{T^{max} - T^{min}}{n}\).
For each fold \(f\in[0,n-(n_{train}+n_{test})+1]\), the buckets from \(b_{f}\) to \(b_{f+n_{train}}\) constitute the training dataset, and the buckets from \(b_{f+n_{train}}\) to \(b_{f+n_{train}+n_{test}}\) form the validation dataset.
Example with \(n = 5\), \(n_{train} = 2\) and \(n_{test} = 1\).

Validation Datasets¶
--validation-mode ValidationDatasets --validation-datasets <validation_datasets>
The whole dataset <dataset> constitutes the training data, and
the list <validation_datasets> constitutes the validation data.
In this validation mode, the validation datasets can be processed as a stream
by specifying --streaming. In this case, the validation instances are not
loaded into memory at once which allows to process bigger datasets.
The batch size of the streaming process can be specified with the optional
argument --stream-batch <size> (default value: 1000).
Unlabeled / Labeled¶
--validation-mode UnlabeledLabeled
This validation mode is available if partial annotations are provided as input : the labeled instances are used as training data, and the unlabeled instances as validation data. In this case, the validation performance cannot be assessed, but the predictions on the validation dataset can be analyzed from the web user interface.
Graphical User Interface¶
Model Performance and Predictions¶
DIADEM displays the performance evaluation and the predictions of the detection model both on the training and validation datasets. The predictions analysis is always available, while the performance evaluation can be computed only when the data are annotated.
Performance. The Performance tab displays the detection and the false alarm rates for a given detection threshold. The value of the detection threshold can be modified through a slider to see the impact on the detection and false alarm rates. The confusion matrix and the ROC curve are also displayed. See Detection Performance Metrics for more information.
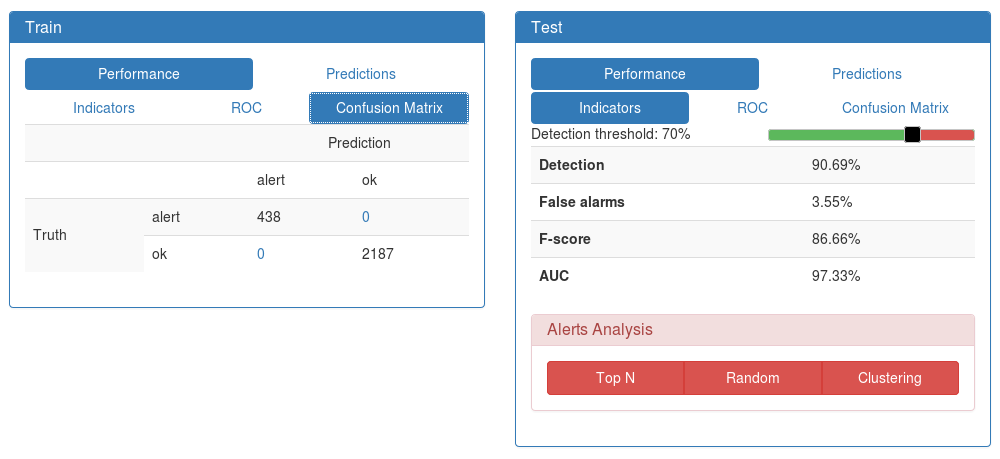
Performance Tab¶
Predictions. The Predictions tab displays the histograms of the predicted probabilities of maliciousness. When annotations are available, the instances are grouped by label.
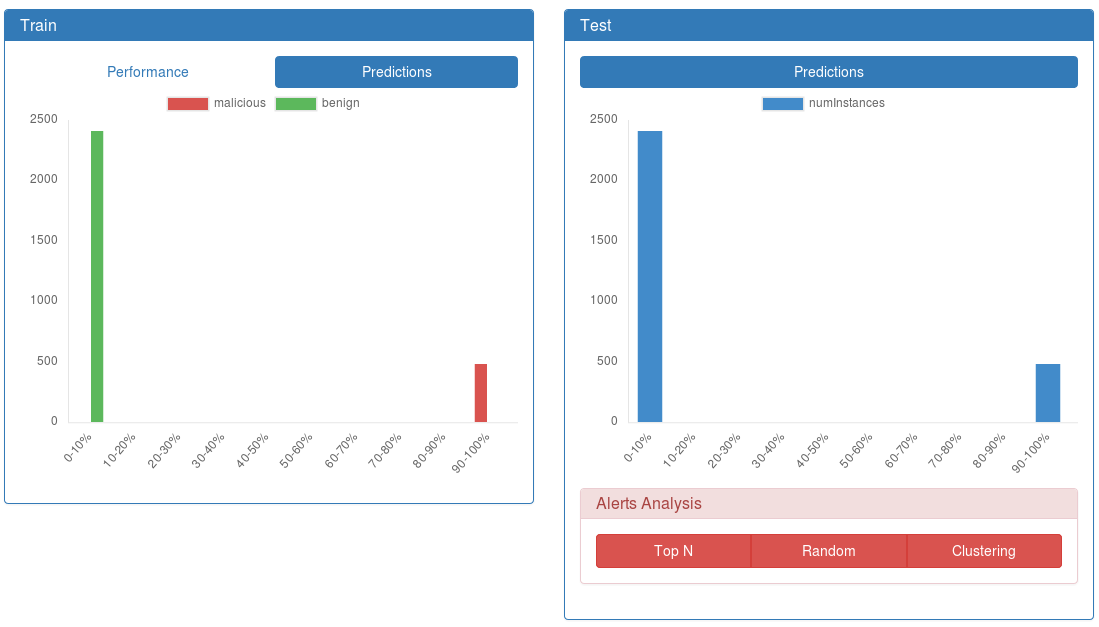
Predictions Tab¶
Model Behavior¶
DIADEM displays information about the global behavior of detection models. This visualization allows to grasp how detection models make decisions and to diagnose potential training biases.
It is currently implemented for linear (see Features Coefficients of a Linear Model) and tree-based (see Features Importance of a Tree-based Model) models. DIADEM does not yet support model-agnostic interpretation methods.
These graphic depictions allow a focus on the most influential features of the detection model. Clicking on a given feature gives access to its descriptive statistics on the training data (see Features Analysis). These statistics allow to understand why a feature has a significant impact on decision-making, and may point out biases in the training dataset.
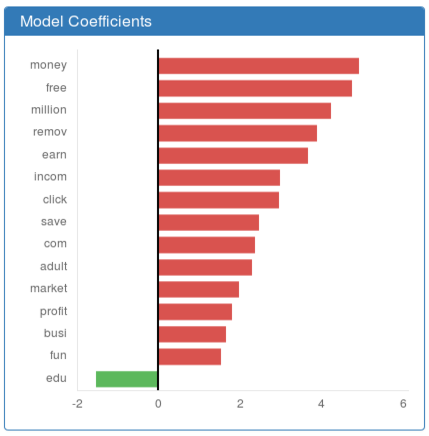
Features Coefficients of a Linear Model¶
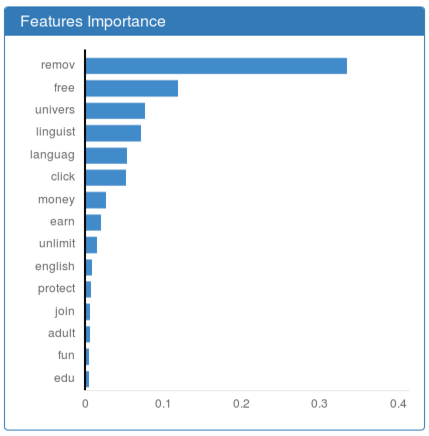
Features Importance of a Tree-based Model¶
Individual Predictions¶
DIADEM diagnosis interface also allows to examine individual predictions. For example, the false positives and negatives can be reviewed by clicking on the confusion matrix displayed in the Performance Tab.
Besides, the Predictions Tab allows to analyze the instances whose predicted probability is within a given range. For instance, the instances close to the decision boundary (probability of maliciousness close to 50%) can be reviewed to understand why the detection model is undecided. Moreover, the instances that have been misclassified with a high level of confidence can be inspected to point out potential annotation errors, or help finding new discriminating features.
Description Panel
DIADEM displays each instance in a Description panel. By default, all the values of the features of the instance are displayed. Other visualizations specific to the detection problem may be more relevant to analyze individual predictions. In order to address this need, SecuML enables users to plug problem-specific visualizations.
If an interpretable model has been trained, DIADEM also displays the features that have the most impact on the prediction (see Most Important Features ). This visualization is easier to interpret than the previous one since the features are sorted according to their impact in the decision-making process.
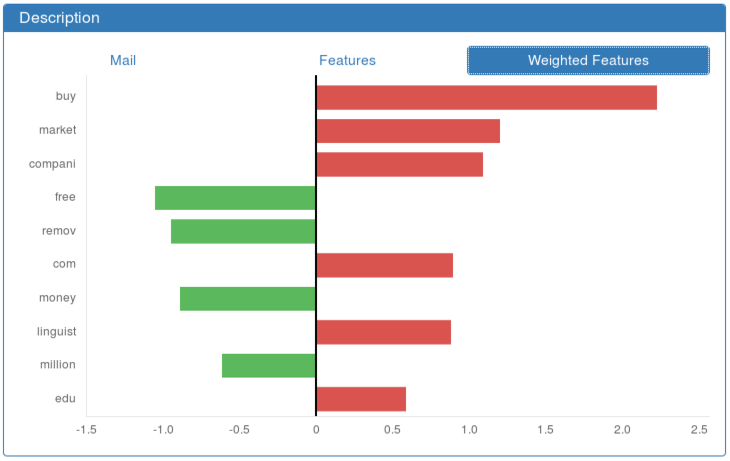
Most Important Features¶