Features Analysis¶
This module provides an overview of input datasets. It displays
the boxplot, the histogram and the distribution of the values of each feature.
If annotations are provided
(with -a GROUND_TRUTH or -a <partial_annotations>.csv)
the analyses are carried out for each label (malicious and benign)
independently and the discriminating power of each feature is assessed
with various indicators
(chi2,
f_classif, and
mutual information).
Features analysis should be executed before running more complex algorithms such as clustering or training a classification model. Indeed, this module can help detect bugs in the feature extraction process (e.g. a feature defined as a ratio that does not have all its values between 0 and 1). Besides, it allows to identify useless features those variance is null on a given dataset.
SecuML_features_analysis <project> <dataset>.SecuML_features_analysis <project> <dataset> -h.Graphical User Interface¶
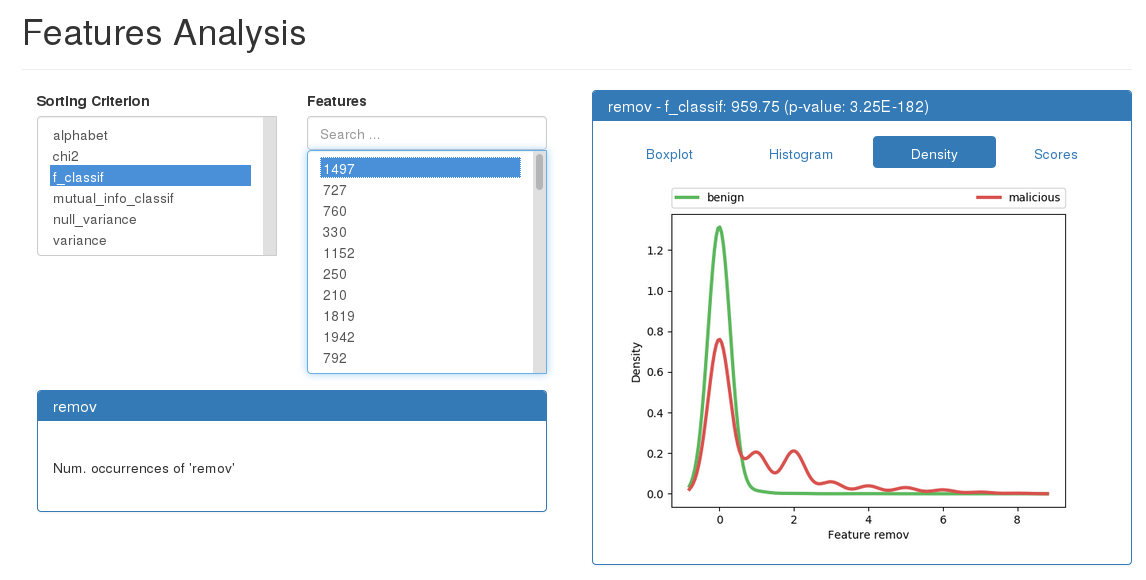
The graphical user interface displays the boxplot, the histogram and the distribution of the values of each features.
The features are listed with their ids (see Data). The panel at the bottom left displays the name and the description of the feature if provided in a description file.
The features can be sorted alphabetically, according to their discriminating
power (if annotations are provided) or according to their variance.
Features with a null variance on the input dataset can be set apart
with the null_variance sorting criterion.